This tutorial is written for the linux environment and uses SSH as the communication protocol.
First, we need an IAM user that has full access to the AWS CodeCommit service. You can either create a new user and attach the appropriate policy to it or use an existing user.
Next, we install Git on the instance.
In order to associate the IAM user with full CodeCommit access with the EC2 instance, we will create an ssh-key pair on the instance and link it with the IAM user through the AWS console. While logged in to the instance, perform the following steps <ul style="list-style-type: disc;">
ssh-keygen
Enter a file name. Example code_commit
Enter the passphrase if required and press enter
This will generate two files: The private key file code_commit and the public key file code_commit.pub. Copy the contents of the public key and save it (we’ll require it in the following steps)
</ul>
Go to the IAM console, choose Policies and then select IAMUserSSHKeys. Click on Attach and then select the IAM user we created/chose in the first step. Click on Attach Policy
Go back to the IAM console and click on Users. Select our IAM user, scroll down and click on Upload SSH public key. Paste the text you copied previously and click Upload SSH public key
Copy the SSH Key ID that will be generated and save it
Inside the instance, create a file “config” inside ~/.ssh with the following contents
Save the file and modify permissions: <ul style="list-style-type: disc;">
chmod 600 config
</ul>
Test the SSH connection to CodeCommit <ul style="list-style-type: disc;">
Setting up CloudWatch Custom Metrics on your instance allows you to monitor resources in addition to the default metrics of CPU Utilization, Disk I/O and Network I/O provided by default. Custom Metrics includes the following additional metrics:
memory-used
memory-utilization
memory-available
swap-utilization
swap-used
disk-space-utilization
disk-space-used
disk-space-availability
These steps are written specifically for Ubuntu. The steps vary for different distributions.
SSH into your EC2 instance
Install the required dependencies: <ul style="list-style-type: square;">
Add access key and secret key to the configuration file. Edit the awscreds.template located inside aws-scripts-mon directory file to add your Access Key and Secret Key. <ul style="list-style-type: square;">
cd aws-scripts-monecho "AWSAccessKeyId=****" > awscreds.template echo "AWSSecretKey=****" >> awscreds.template
</ul>
Set environment variable & export the path of the credential file <ul style="list-style-type: square;">
Create a cronjob. Add the monitoring script to the crontab. Run it every 5 minutes or choose a time cycle according to your requirements. <ul style="list-style-type: square;">
With an increasing number of websites and web applications moving their infrastructure to AWS from the traditional “web hosting” services, it has become important to ensure that this shift is done properly and in a well-planned manner. Doing so ensures that the application is able to make the most of the benefits AWS has to offer like Scalability, High Availability, Fault Tolerance, Content Distribution Networks and so on.
Below is a guide on how to leverage the infrastructure provided by AWS to create a highly scalable and fault tolerant web architecture.
1) Create a VPC
The first step is to create a Virtual Private Cloud with a CIDR IP range of your choice. The block size should be between /16 and /28
A nice, blank canvas for us to work on
2) Create subnets
Next step is to create subnets under the VPC. For our architecture, we’ll design two private subnets in two different availability zones.
Two subnets corresponding to two different Availability Zones in order to implement High Availability
3) Adding an Internet Gateway
In order for the instances to access the internet, we must attach an Internet Gateway to the VPC. We’ll first create an Internet Gateway and then attach it to our VPC. In addition to this, we need to edit the Route Tables being used by the two subnets (a route table is created automatically whenever a VPC is created and all the subnets created inside the VPC get implicitly associated with this route table).
Edit the Route Table and add “0.0.0.0/0” to the Target field and select the IGW (Internet Gateway) in the Destination field. This will direct all traffic headed towards “0.0.0.0/0” to the IGW which will then route it to the appropriate destination.
IGW allows communicating with internet
4) Launch Instances
We only require one instance each for the Web Layer and the Application Layer. The instance will be added to corresponding Auto-Scaling groups (one for Web Layer and one for Application Layer) which will automatically increase or decrease the number of instances in the group.
<figcaption class="wp-caption-text">Launch a single instance of the Web and App servers</figcaption></figure>
5) Create Load Balancers
Create two Elastic Load Balancers, for the Web Layer and Application Layer respectively. While creating it, configure the ELBs to span both the subnets.
<figcaption class="wp-caption-text">Load balancers for the Web and App layer respectively</figcaption></figure>
6) **Create Auto-Scaling Group and attach it to Load Balancer
**
There are three steps under this.
i) After configuring the Web and Application servers launched above, create an AMI of both.
ii) Create two Auto-Scaling groups for both the Web and Application Layers using the AMIs created in the above step.
iii) Attach the Web Layer Auto-Scaling group to the Web Layer ELB and the Application Layer Aut0-Scaling group to the Application Layer ELB
<figcaption class="wp-caption-text">Create two AutoScaling groups and attach it to the corresponding ELBs</figcaption></figure>
7) Add the third Database Layer
Add an RDS instance in Multi-AZ mode which will create a standby RDS instance.
<figcaption class="wp-caption-text">RDS the third layer of the architecture</figcaption></figure>
8) Create CloudFront Distribution using ELB endpoint
<figcaption class="wp-caption-text">Create a CloudFront distribution using the Web Layer ELB endpoint</figcaption></figure>
9) Add an S3 bucket to store static content. Connect CloudFront to this bucket.
<figcaption class="wp-caption-text">Store static content on S3 and connect it to CloudFront to S3 which will cache and serve the content</figcaption></figure>
10) Map your domain to the CloudFront Distribution URL by using Route 53 to configure a CNAME record.
<figcaption class="wp-caption-text">Create a CNAME record using CloudFront Distribution URL on Route 53</figcaption></figure>
By following this design methodology, we can ensure that our architecture is capable of utilizing scalable infrastructure. It is important to identify the components in your architecture that can potentially cause bottlenecks. By refactoring such components, your infrastructure can be made non-blocking. It is also equally important to ensure that your application plays well with scalability. Ideally, your application should be stateless in nature and highly decoupled.
In this way, you are ready to exploit the cloud and fully leverage the benefits it has to offer.
(l = long description, a = all files including the ones starting with “.”)
How to create partition on a device
parted /dev/sdb (select device)
print (view existing partitions on device)
rm (deletes selected partition)
mklabel msdos (assigns “msdos” label to un-labelled partitions)
mkpart primary 1G 2G
(creates a primary partition of size 1GB from block 1GB to 2GB)
View newly created partitions
fdisk -l /dev/sdb
Format partition with preferred filesystem
mkfs.ext2 /dev/sdb1<br />
mkfs.ext4 /dev/sdb2
Mounting filesystems
mount -o noatime /dev/sdb1 /mnt
(where, -o is options, ‘noatime’ is “no access times” which prevents access times from being written to the inode which results in better performance. /dev/sdb1 is the partition and /mnt is the mount point)
In addition to ‘noatime’ other options include
async : File operations take place asynchronoulsy
ro : Partition mounted in read-only mode
noexec : Ignores any “execute bits” on the filesystem. Used for security purposes.
nosuid : Ignores any setuserid bits on the filesystem. Used for security purposes.
remount : Remounts in preferred mode. Example mount -o remount, rw /boot
Shells
Editor Shortcuts
Ctrl-b: Move backward by one character
Ctrl-f: Move forward by one character
Ctrl-a: Move to the beginning of the line
Ctrl-e: Move to the end of the line
Ctrl-k: Delete from the cursor forward
Ctrl-u: Delete from the cursor backward
Ctrl-r: Search the command history
Environment Variables
Environment variables are used to define often-used attributes by the shell. Most common environment variables are
$PATH: Specifies the set of directories the shell will search for commands
To list all environment variables
env
Shell Profiles
Shell profiles define a user’s environment. Environment variables can be set in a profile. There are two types of profiles.
/etc/profile: Global profile. This is the default profile.
~/.profile : This is a user specific profile. Any environment variable set in this profile applies to only that specific user.
Note: ~/.profile is executed after /etc/profile. It is possible to override this.
Special Environment Variables
Command
Description
$$
Process ID of current shell
$!
Background process ID
$?
Exit status. ‘0’ means success. Any non-zero number indicates an error.
history
Provides history of commands executed on shell
!!
Re-executes previous command
ctrl+R
Searches the command history
jobs
List background jobs
&
Executes job in background. Ex: sleep 50 &
fg
Brings background job to foreground.
bg
Sends the job to the background
fg %d
Brings the job specified by the job ID (‘d’) to the foreground
kill %d
Kills the specified job ID
Package Management
Package Managers
APT (Used by Debian, Ubuntu) and RPM (Used by RedHat, CentOS, SUSE, Fedora) are the two most popular package managers.
Yum provides a wrapper around RPM which allows to install from multiple package repositories. It also resolves dependencies.
Installing Packages
yum install dstat<br />
rpm -i dstat-0.3.9.rpm(where -i is install)
Upgrading Packages
yum install dstat
To upgrade all packages run:
yum upgrade<br />
rpm -Uvh dstat-0.3.9.rpm
(where -U is Upgrade, v is verbose and h is hash (displays hash signs))
Uninstalling Packages
yum remove dstat<br />
rpm -e dstat
Cleaning RPM Database
yum clean all (removes all refresh package metadata next time)
Boot Process
Power Supply Unit
When the power switch is turned on, the internal electrical circuit is complete and the PSU starts getting power. It performs a self-test after which it notifies the CPU through the 4-pin connector that the CPU should power on.
After the CPU has powered up, the first call is made to the BIOS. The first step taken by the BIOS is to ensure the minimum hardware exists.
The BIOS can be programmed with firmware. Firmware is the software that is programmed into Electrically Erasable Programmable Read-Only Memory (EEPROM). In this case, the firmware facilitates booting an operating system and configuring basic hardware settings.
After confirming the existence of the CPU, Memory and Video Card, the BIOS configures them using CMOS. The CMOS serves as the memory of the BIOS where information like memory frequency and CPU frequency is stored. BIOS first sets the memory frequency on the memory controller an then multiplies the memory frequency by CPU frequency multiplier. This product is the speed at which the CPU runs.
After setting the frequencies the BIOS performs POST (Power-on Self Test) where it checks if <ol style="list-style-type: lower-alpha;">
The memory is working
Hard drives and other devices are responding
Keyboard and mouse are connected
Initialize any additional BIOSes (eg. RAID cards)
</ol>
The system may beep in case the POST fails. One beep indicates success, three successive beeps indicate memory error and one long beep followed by two short beeps indicate a video card or display problem.
Next, based on the boot order set through the BIOS, the device for booting is selected. Supported devices are CD-ROMs, USB flash drives, Hard Drives, a network.
After selecting the particular drive to boot from, it looks at the first sector of that drive to find the boot sector. There are two main types of boot sectors/partition tables.
Master Boot Record (MBR)
Has two parts. Boot loader information block (448 bytes) and the partition table (64 bytes)
Boot loader is where the first program the computer can run is stored.
Partition table stores the logical layout of the drive
Since the space provided by the boot loader was becoming insufficient, a process called “chain boot loading” is used where the first program residing in the bootloader loads other programs from elsewhere into the memory is used. This new program then continues the boot process.
GPT – GUID Partition Way
Partitions are identified by Globally-unique ID (GUID) rather than partition numbers (MBR).
It supports unlimited partitions.
The address space allows storage devices greater than 2TB (limitation of MBR)
A backup copy of the partition table is stored at the end of the disk.
Bootloader
The purpose of the bootloader is to load the initial kernel and supporting modules into the memory. GRand Unified Bootloader (GRUB) is a widely used bootloader by many Linux distributions. GRUB is a “chain bootloader” and initialises itself in these stages
Stage 1: A very tiny application that can exist in the first part of the drive, it exists to load the next, larger part of the GRUB
Stage 1.5: Contains the drivers necessary to load the filesystem in Stage 2.
Stage 2: This stage loads the menu and config options for GRUB
Kernel and Init
The kernel is the main component of an OS which manages the memory and processor related tasks and also handles the various device drivers of different devices. Since it’s not possible to store every device driver in the kernel (it affects the boot speed), a component called RAM disk (part of RAM as a disk drive) is used on which enough drivers are used so that the kernel can load filesystem where the other drivers are located.
The init system is defined as the organizational scheme for loading the system services. The most common init system in Linux is called “System V init”.
After the ramdisk helps the kernel access the hard drive, the first process is run. i.e. /bin/init.
Runlevels
The init process reads from /etc/inittab to figure out which script to run. These scripts are run or not run based on the desired “runlevel” of the system.
The six runlevels are:
0: Halt the system
1: Singler-user mode (for special administration/troubleshooting)
2: Local Multiuser with Networking but without network service (like NFS)
3: Full Mutliuser with Networking
4: Not Used
5: Full Multiuser with Networking and X Windows(GUI)
top shows the most CPU intensive processes in tabular format and refreshes it every second. Pressing m when top is running will sort the processes by memory usage rather than the default of processor usage.
du -h : Returns the information in human readable form
If a directory is provided as an argument to the command, it will return a value for each file in the directory. du -sh which will give a sum of all the files under the specified directory.
cat /home/foo.txt: Outputs contents of file “foo.txt” on the shell
cat /tmp/foo.txt /home/jdoe/bar.txt > /home/jdoe/foobar.txt:Outputs contents of files “foo.txt” and “bar.txt” to “foobar.txt” (will overwrite contents of “foobar.txt” if any)
sort is used to sort lines of text using parameters
The default action sorts the lines alphabetically
cat coffee.txt
Mocha
Cappuccino
Espresso
Americano
sort coffee.txt
Americano
Cappuccino
Espresso
Mocha
The -r flag sorts it in reverse order
sort -r coffee.txt
Mocha
Espresso
Cappuccino
Americano
For number sorting, use the -n flag
sort orders.txt
1003 Americano
100 Mocha
25 Cappuccino
63 Espresso
sort -n orders.txt
25 Cappuccino
63 Espresso
100 Mocha
1003 Americano
history
It gives you a list of commands that were run by the current user. These commands are stored in a hidden file called “bash_history” located in the user’s home directory. The command history are accompanied by a index number. In order to clear a specific command use
history -d <line-number>
To clear multiple lines, say lines 1800 to 1815 write the following in To clear lines from let’s say line 1800 to 1815 , use the following command:
for line in $(seq 1800 1815) ; do history -d 1800; done
If you want to delete the history for the deletion command, write 1816 (1815 +1) and the history for that sequence will be deleted along with the deletion command too.
Welcome to my blog. This is where I jot down the things my mind happens to retain when I’m tinkering with various tools and technologies. A systematic braindump, I call it. Hope you find it useful.
 A nice, blank canvas for us to work on
A nice, blank canvas for us to work on Two subnets corresponding to two different Availability Zones in order to implement High Availability
Two subnets corresponding to two different Availability Zones in order to implement High Availability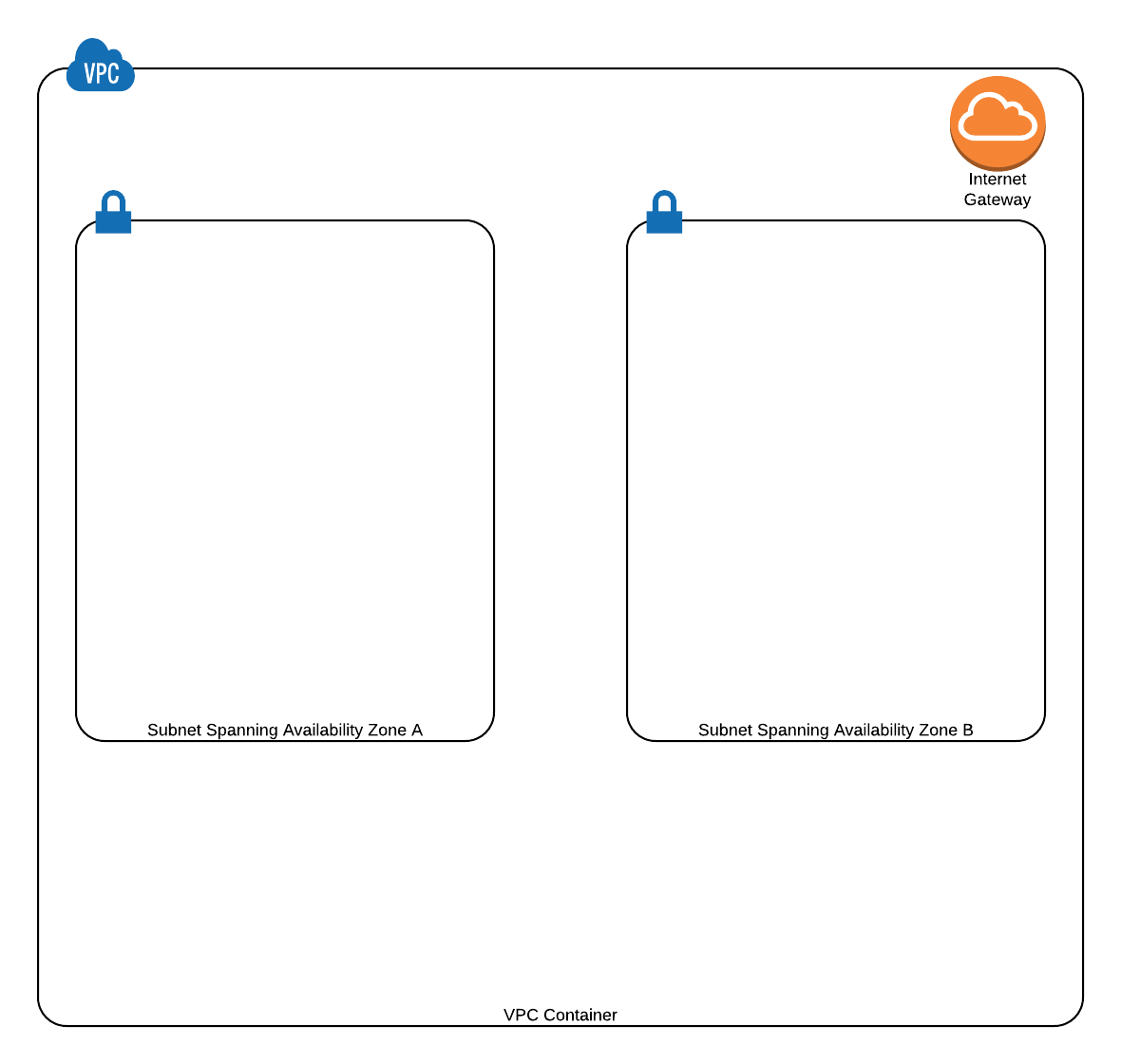 IGW allows communicating with internet
IGW allows communicating with internet





